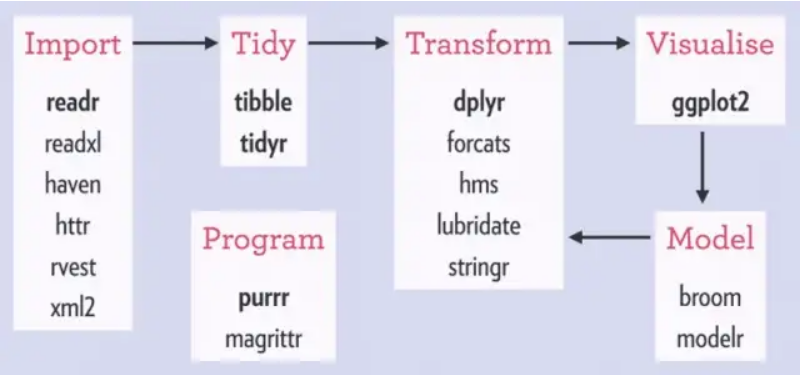
El manejo de datos (carga, limpieza, orden, visualización, modelado, ver imagen de abajo) es una de las tareas a las que mayor tiempo le dedicaremos cuando estemos trabajando con R. Uno de los paquetes más utilizados para llevar adelante esta tarea es dplyr. Este paquete forma parte del tidyverse y contiene una serie de funciones que nos dejaran seleccionar, renombrar, filtrar, re-acomodar y resumir las variables de nuestra base de datos. Conviene pensar en dplyr como una gramática para el manejo de datos.
Datos utilizaremos
Aca la realidad es que se pueden utilizar todo tipo de bases de datos. Se podrían usar las bases que vienen en el mismo R como por ejemplo iris o también la base de pinguinos del paquete palmerpenguins. Esas bases siempre las tendremos a disposición. Sin embargo hoy vamos a trabajar con algunas funciona de dplyr utilizando una base con datos bibliométricos que fue generada utilizando la herramienta Constellate de jstor. Esta base es bastante cercana a lo que podriamos conseguir en “el mundo real” porque tiene datos faltantes, esta re desordanada, tiene malos nombres de variables etc…
Para acceder a los datos podemos hacer click aca o directamente entrar al repositorio y descargarlos manualmente: https://osf.io/bwdvy/?view_only=
Una vez descargados los datos es conveniente guardarlos en la carpeta datos de nuestro proyecto.
Otra opción es ejecurtar este codigo. De esta manera la funcion dowload.file tomara la url que ingresemos, desgarcará el archivo y lo guardará donde le indiquemos. En este caso en la carpeta datos de nuestro proyecto
ATENCIÓN!!
Para que esto funcione ya debemos tener creada la carpeta datos en nuestro proyecto
Ver/Ocultar código
download.file(url ="https://osf.io/download/cp2kz", # URL donde esta el archivo a descargardestfile ="datos/datos_cdc.csv") # carpeta donde se guardara el archivolibrary(readr) # Para leer datosdatos_cdc <-read_csv("datos/datos_cdc.csv") # Funcion para leer datos csv (separados por coma)glimpse() # Esto es para darle un vistazo a la base
Pero… ¿Cómo?
Podemos pensar el manejo de datos con dplyr como si las funciones del paquete fueran verbos. Cuales son esos verbos?
Esta función maneja los datos según sus filas. Lo que hace es filtrar datos según la lógica que le indiquemos.
Seleccionar
select()
Esta funciona maneja los datos según las columnas. Lo que hace es seleccionar (o también quitar) variables (columnas de nuestra base de datos)
Crear
mutate()
Esta función también modifica columnas y lo que hace es crear variables nuevas.
Ordenar
arrange()
Esta función maneja según las filas de alguna columna seleccionada. Lo que hace es ordenar la base de datos de menor a mayor (o viceversa) segun los datos de una variable. Básicamente es como el botón de Ordenar y Filtrar de excel.
Acomodar
relocate()
Esta función también trabaja con columnas y lo que hace es re-ordenarlas. Emula lo que comúnmente se hace con el mouse. Indicamos que variables queremos mover y hacia donde.
Renombrar
rename()
Esta función trabaja con columnas y lo que hace es renombrarlas. El orden es: nombre nuevo = nombre viejo
Resumir
summarise()
Esta función genera un resumen de nuestros datos ya sean generales o agrupados utilizando la función de abajo group_by()
Agrupar
group_by()
Esta función agrupa los datos según una variable categórica en particular.
La manera de utilizar estas herramientas es bastante simple. Se escribe la función que necesitemos, se indican los datos en los que vamos a trabajar y luego se indica aquello que necesitemos hacer.
Filtrar
Ver/Ocultar código
library(tidyverse)
Warning: package 'tidyverse' was built under R version 4.2.2
Warning: package 'ggplot2' was built under R version 4.2.2
Warning: package 'tibble' was built under R version 4.2.2
Warning: package 'tidyr' was built under R version 4.2.2
Warning: package 'readr' was built under R version 4.2.2
Warning: package 'purrr' was built under R version 4.2.2
Warning: package 'dplyr' was built under R version 4.2.2
Warning: package 'stringr' was built under R version 4.2.2
Warning: package 'forcats' was built under R version 4.2.2
Pseudocodigo
Ver/Ocultar código
funcion(datos, lo que necesitamos)
Pseudocodigo con un objetivo más claro
Ver/Ocultar código
filtrar(datos, variable mayor que 1)
Codigo para alcanzar el objetivo
Ver/Ocultar código
filter(.data = starwars, height >175) # En este caso solo necesito aquellos datos de quienes tengan una altura mayor a 175 cm
# A tibble: 48 × 14
name height mass hair_…¹ skin_…² eye_c…³ birth…⁴ sex gender homew…⁵
<chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr> <chr>
1 Darth Vader 202 136 none white yellow 41.9 male mascu… Tatooi…
2 Owen Lars 178 120 brown,… light blue 52 male mascu… Tatooi…
3 Biggs Dark… 183 84 black light brown 24 male mascu… Tatooi…
4 Obi-Wan Ke… 182 77 auburn… fair blue-g… 57 male mascu… Stewjon
5 Anakin Sky… 188 84 blond fair blue 41.9 male mascu… Tatooi…
6 Wilhuff Ta… 180 NA auburn… fair blue 64 male mascu… Eriadu
7 Chewbacca 228 112 brown unknown blue 200 male mascu… Kashyy…
8 Han Solo 180 80 brown fair brown 29 male mascu… Corell…
9 Jek Tono P… 180 110 brown fair blue NA male mascu… Bestin…
10 Boba Fett 183 78.2 black fair brown 31.5 male mascu… Kamino
# … with 38 more rows, 4 more variables: species <chr>, films <list>,
# vehicles <list>, starships <list>, and abbreviated variable names
# ¹hair_color, ²skin_color, ³eye_color, ⁴birth_year, ⁵homeworld
Ver/Ocultar código
filter(.data = starwars, species =="Wookiee") # En este caso solo necesito los datos de quienes sean de la especie Wookiee
# A tibble: 2 × 14
name height mass hair_color skin_…¹ eye_c…² birth…³ sex gender homew…⁴
<chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr> <chr>
1 Chewbacca 228 112 brown unknown blue 200 male mascu… Kashyy…
2 Tarfful 234 136 brown brown blue NA male mascu… Kashyy…
# … with 4 more variables: species <chr>, films <list>, vehicles <list>,
# starships <list>, and abbreviated variable names ¹skin_color, ²eye_color,
# ³birth_year, ⁴homeworld
Seleccionar
Pseudocodigo
Ver/Ocultar código
seleccionar(datos, variable(s) de interes)
Código
Ver/Ocultar código
select(.data = starwars, c(name, height, mass, gender)) # En este caso solo me interesaban las variables nombre, altura, masa y genero
# A tibble: 87 × 4
name height mass gender
<chr> <int> <dbl> <chr>
1 Luke Skywalker 172 77 masculine
2 C-3PO 167 75 masculine
3 R2-D2 96 32 masculine
4 Darth Vader 202 136 masculine
5 Leia Organa 150 49 feminine
6 Owen Lars 178 120 masculine
7 Beru Whitesun lars 165 75 feminine
8 R5-D4 97 32 masculine
9 Biggs Darklighter 183 84 masculine
10 Obi-Wan Kenobi 182 77 masculine
# … with 77 more rows
Ver/Ocultar código
seleccion1 <-select(.data = starwars, c(name, height, mass, gender))select(.data = seleccion1, -height) # En este caso se puede usar el select para quitar una variable. Eso se hace usando un - antes de la variable que queremos quitar.
# A tibble: 87 × 3
name mass gender
<chr> <dbl> <chr>
1 Luke Skywalker 77 masculine
2 C-3PO 75 masculine
3 R2-D2 32 masculine
4 Darth Vader 136 masculine
5 Leia Organa 49 feminine
6 Owen Lars 120 masculine
7 Beru Whitesun lars 75 feminine
8 R5-D4 32 masculine
9 Biggs Darklighter 84 masculine
10 Obi-Wan Kenobi 77 masculine
# … with 77 more rows
Ver/Ocultar código
select(.data = starwars, starts_with("h"))
# A tibble: 87 × 3
height hair_color homeworld
<int> <chr> <chr>
1 172 blond Tatooine
2 167 <NA> Tatooine
3 96 <NA> Naboo
4 202 none Tatooine
5 150 brown Alderaan
6 178 brown, grey Tatooine
7 165 brown Tatooine
8 97 <NA> Tatooine
9 183 black Tatooine
10 182 auburn, white Stewjon
# … with 77 more rows
Crear
Pseudocodigo
Ver/Ocultar código
crear(datos, variable(s) que necesito crear = contenido)
Código
Ver/Ocultar código
mutate(.data = seleccion1, altura = height/100) # En este caso vamos a crear una nueva variable que contenta la transformacion de height de centimetros a metros
# A tibble: 87 × 5
name height mass gender altura
<chr> <int> <dbl> <chr> <dbl>
1 Luke Skywalker 172 77 masculine 1.72
2 C-3PO 167 75 masculine 1.67
3 R2-D2 96 32 masculine 0.96
4 Darth Vader 202 136 masculine 2.02
5 Leia Organa 150 49 feminine 1.5
6 Owen Lars 178 120 masculine 1.78
7 Beru Whitesun lars 165 75 feminine 1.65
8 R5-D4 97 32 masculine 0.97
9 Biggs Darklighter 183 84 masculine 1.83
10 Obi-Wan Kenobi 182 77 masculine 1.82
# … with 77 more rows
A tener en cuenta!
Cuando usemos mutate() con una variable que ya existe en el dataset conviene no sobreescribirla. Esto afectaría la reproducibilidad del código. Lo mejor es generar una nueva variable con algún identificador.
Por ejemplo: Cuando cargamos el dataset vemos que la variable de agrupación gender es de tipo chr y lo que necesitamos es que sea un factor. En ese caso se haría lo siguiente:
Ver/Ocultar código
mutate(.data = seleccion1, gender_fct =as_factor(gender)) # Nos quedan ambas variables y solo utilizamos la que necesitemos
# A tibble: 87 × 5
name height mass gender gender_fct
<chr> <int> <dbl> <chr> <fct>
1 Luke Skywalker 172 77 masculine masculine
2 C-3PO 167 75 masculine masculine
3 R2-D2 96 32 masculine masculine
4 Darth Vader 202 136 masculine masculine
5 Leia Organa 150 49 feminine feminine
6 Owen Lars 178 120 masculine masculine
7 Beru Whitesun lars 165 75 feminine feminine
8 R5-D4 97 32 masculine masculine
9 Biggs Darklighter 183 84 masculine masculine
10 Obi-Wan Kenobi 182 77 masculine masculine
# … with 77 more rows
Ordenar
Pseudocodigo
Ver/Ocultar código
ordenar(datos, variable seleccionada)
Código
Ver/Ocultar código
arrange(.data = starwars, height) # Orden de menor a mayor
# A tibble: 87 × 14
name height mass hair_…¹ skin_…² eye_c…³ birth…⁴ sex gender homew…⁵
<chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr> <chr>
1 Yoda 66 17 white green brown 896 male mascu… <NA>
2 Ratts Tyer… 79 15 none grey, … unknown NA male mascu… Aleen …
3 Wicket Sys… 88 20 brown brown brown 8 male mascu… Endor
4 Dud Bolt 94 45 none blue, … yellow NA male mascu… Vulpter
5 R2-D2 96 32 <NA> white,… red 33 none mascu… Naboo
6 R4-P17 96 NA none silver… red, b… NA none femin… <NA>
7 R5-D4 97 32 <NA> white,… red NA none mascu… Tatooi…
8 Sebulba 112 40 none grey, … orange NA male mascu… Malast…
9 Gasgano 122 NA none white,… black NA male mascu… Troiken
10 Watto 137 NA black blue, … yellow NA male mascu… Toydar…
# … with 77 more rows, 4 more variables: species <chr>, films <list>,
# vehicles <list>, starships <list>, and abbreviated variable names
# ¹hair_color, ²skin_color, ³eye_color, ⁴birth_year, ⁵homeworld
Ver/Ocultar código
arrange(.data = starwars, desc(height)) # Orden de mayor a menor
# A tibble: 87 × 14
name height mass hair_…¹ skin_…² eye_c…³ birth…⁴ sex gender homew…⁵
<chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr> <chr>
1 Yarael Poof 264 NA none white yellow NA male mascu… Quermia
2 Tarfful 234 136 brown brown blue NA male mascu… Kashyy…
3 Lama Su 229 88 none grey black NA male mascu… Kamino
4 Chewbacca 228 112 brown unknown blue 200 male mascu… Kashyy…
5 Roos Tarpa… 224 82 none grey orange NA male mascu… Naboo
6 Grievous 216 159 none brown,… green,… NA male mascu… Kalee
7 Taun We 213 NA none grey black NA fema… femin… Kamino
8 Rugor Nass 206 NA none green orange NA male mascu… Naboo
9 Tion Medon 206 80 none grey black NA male mascu… Utapau
10 Darth Vader 202 136 none white yellow 41.9 male mascu… Tatooi…
# … with 77 more rows, 4 more variables: species <chr>, films <list>,
# vehicles <list>, starships <list>, and abbreviated variable names
# ¹hair_color, ²skin_color, ³eye_color, ⁴birth_year, ⁵homeworld
Acomodar
Pseudocodigo
Ver/Ocultar código
acomodar(datos, variable, antes/despues de)
Código
Ver/Ocultar código
relocate(.data = seleccion1, gender, .after = name) # En este caso acomodamos gender despues de name
# A tibble: 87 × 4
name gender height mass
<chr> <chr> <int> <dbl>
1 Luke Skywalker masculine 172 77
2 C-3PO masculine 167 75
3 R2-D2 masculine 96 32
4 Darth Vader masculine 202 136
5 Leia Organa feminine 150 49
6 Owen Lars masculine 178 120
7 Beru Whitesun lars feminine 165 75
8 R5-D4 masculine 97 32
9 Biggs Darklighter masculine 183 84
10 Obi-Wan Kenobi masculine 182 77
# … with 77 more rows
Ver/Ocultar código
relocate(.data = seleccion1, name, .before = mass) # En este caso acomodamos name despues de mass
# A tibble: 87 × 4
height name mass gender
<int> <chr> <dbl> <chr>
1 172 Luke Skywalker 77 masculine
2 167 C-3PO 75 masculine
3 96 R2-D2 32 masculine
4 202 Darth Vader 136 masculine
5 150 Leia Organa 49 feminine
6 178 Owen Lars 120 masculine
7 165 Beru Whitesun lars 75 feminine
8 97 R5-D4 32 masculine
9 183 Biggs Darklighter 84 masculine
10 182 Obi-Wan Kenobi 77 masculine
# … with 77 more rows
Los verbos que proporciona dplyr son geniales y muy faciles de utilizar, pero para todo lo que hicimos más arriba se necesito una linea de codigo para cada verbo. Es decir, cada codigo era independiente del otro. Una gran funcion que permite unificar todos los verbos en un solo programa es la pipa, tuberia o lo que se dice piping.
Les presento a ella %>% el operador del paquete magrittr. Lo que hace es tomar el resultado de una función y pasarla a otra función como argumento. Esto nos permite vincular una secuencia de pasos de análisis. O en otras palabras, utilizar varios verbos de dplyr en un mismo programa.
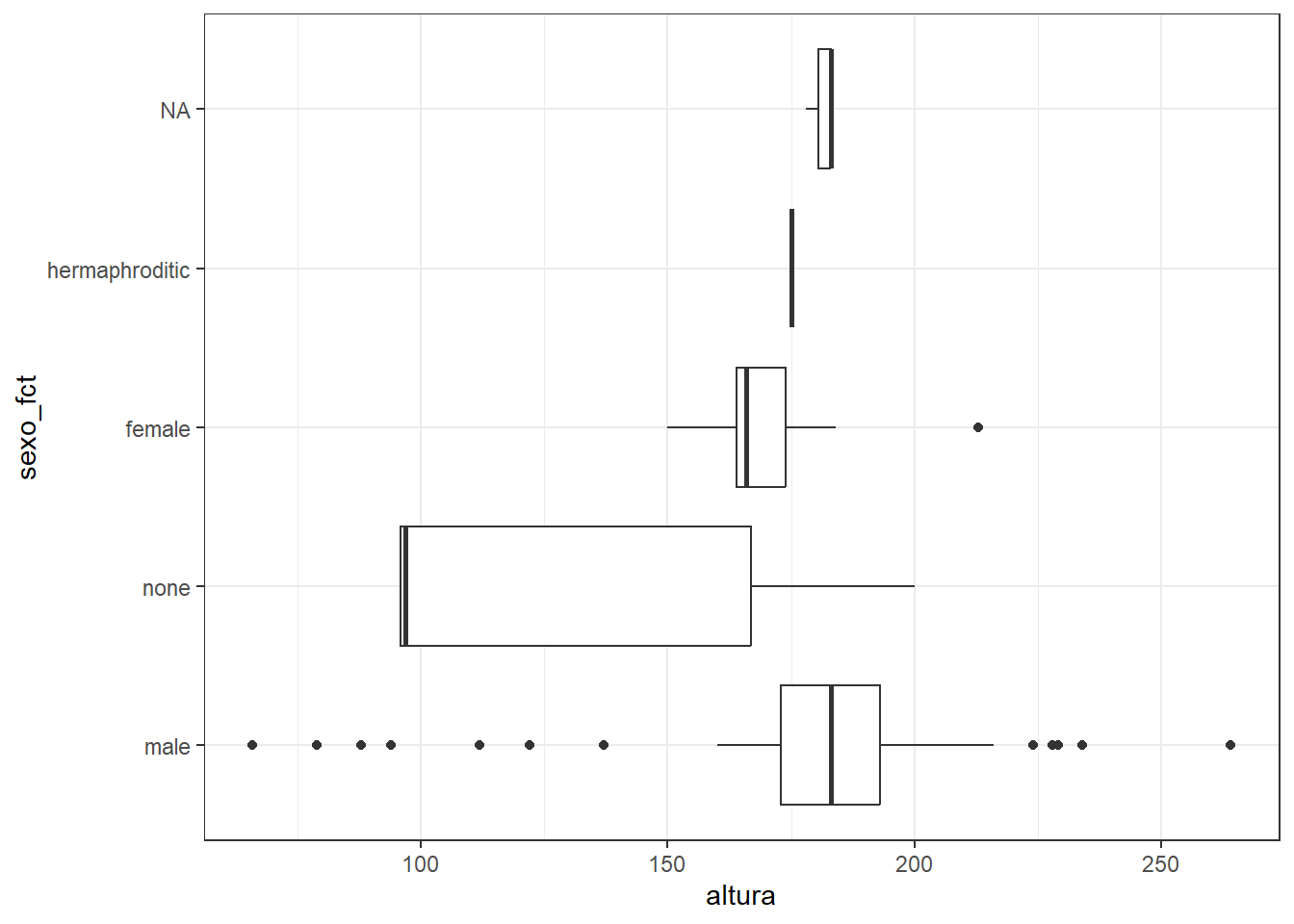
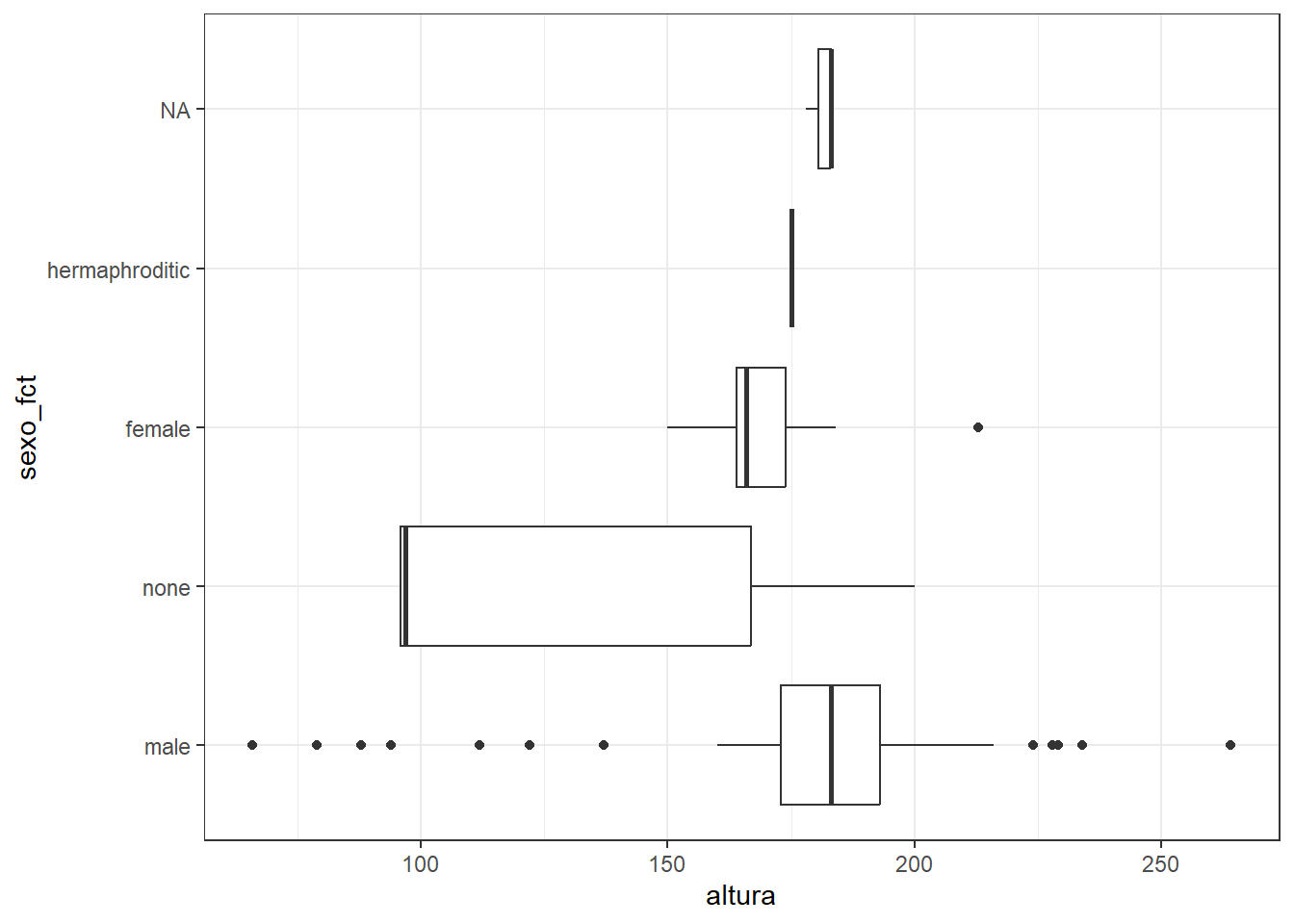
Por ejemplo: Se necesita seleccionar algunas variables, renombrarlas y crear variables que sean del tipo correcto. Por ultimo, graficar la altura según el sexo del personaje
Me encanto la pipa, pero es medio complicada de escribir. Si, es verdad. Para eso usamos el siguiente atajo del teclado CTRL + SHIFT + M y ya tenemos la pipa. Con un poco de practica ya sale sola.
Existe otra pipa que fue introducida recientemente. Yo le digo el pinguinito. Es la pipa nativa de R y es así |>. En general cumple la misma función. Yo como soy viejo y me acostumbre a usar %>% entonces sigo con esa. Ustedes usen la que mas les guste y cumpla mejor con sus objetivos. Hay debate sobre que pipa usar. Quedara para otro momento.
Source Code
---title: "Tercera Reunion"editor: visual---# Manejo de datos: IntroEl manejo de datos (carga, limpieza, orden, visualización, modelado, *ver imagen de abajo*) es una de las tareas a las que mayor tiempo le dedicaremos cuando estemos trabajando con R. Uno de los paquetes más utilizados para llevar adelante esta tarea es `dplyr`. Este paquete forma parte del `tidyverse` y contiene una serie de funciones que nos dejaran `seleccionar`, `renombrar`, `filtrar`, `re-acomodar` y `resumir` las variables de nuestra base de datos. Conviene pensar en `dplyr` como una gramática para el manejo de datos.{fig-align="center"}## Datos utilizaremosAca la realidad es que se pueden utilizar todo tipo de bases de datos. Se podrían usar las bases que vienen en el mismo R como por ejemplo `iris` o también la base de pinguinos del paquete `palmerpenguins`. Esas bases siempre las tendremos a disposición. Sin embargo hoy vamos a trabajar con algunas funciona de dplyr utilizando una base con datos bibliométricos que fue generada utilizando la herramienta Constellate de jstor. Esta base es bastante cercana a lo que podriamos conseguir en "el mundo real" porque tiene datos faltantes, esta re desordanada, tiene malos nombres de variables etc...Para acceder a los datos podemos hacer [click aca](https://osf.io/download/cp2kz) o directamente entrar al repositorio y descargarlos manualmente: https://osf.io/bwdvy/?view_only=Una vez descargados los datos es conveniente guardarlos en la carpeta datos de nuestro proyecto.Otra opción es ejecurtar este codigo. De esta manera la funcion dowload.file tomara la url que ingresemos, desgarcará el archivo y lo guardará donde le indiquemos. En este caso en la carpeta datos de nuestro proyecto::: {.callout-tip collapse="true"}## ATENCIÓN!!Para que esto funcione ya debemos tener creada la carpeta datos en nuestro proyecto:::```{r eval=FALSE}download.file(url ="https://osf.io/download/cp2kz", # URL donde esta el archivo a descargardestfile ="datos/datos_cdc.csv") # carpeta donde se guardara el archivolibrary(readr) # Para leer datosdatos_cdc <-read_csv("datos/datos_cdc.csv") # Funcion para leer datos csv (separados por coma)glimpse() # Esto es para darle un vistazo a la base```## Pero... ¿Cómo?Podemos pensar el manejo de datos con dplyr como si las funciones del paquete fueran verbos. Cuales son esos verbos?| Verbo | Función | Descripción ||---------|---------|-----------------------------------------------------|| Filtrar | `filter()` | Esta función maneja los datos según sus filas. Lo que hace es filtrar datos según la lógica que le indiquemos. || Seleccionar | `select()` | Esta funciona maneja los datos según las columnas. Lo que hace es seleccionar (*o también quitar*) variables (columnas de nuestra base de datos) || Crear | `mutate()` | Esta función también modifica columnas y lo que hace es crear variables nuevas. || Ordenar | `arrange()` | Esta función maneja según las filas de alguna columna seleccionada. Lo que hace es ordenar la base de datos de menor a mayor (*o viceversa*) segun los datos de una variable. **Básicamente es como el botón de Ordenar y Filtrar de excel**. || Acomodar | `relocate()` | Esta función también trabaja con columnas y lo que hace es re-ordenarlas. Emula lo que comúnmente se hace con el mouse. Indicamos que variables queremos mover y hacia donde. || Renombrar | `rename()` | Esta función trabaja con columnas y lo que hace es renombrarlas. El orden es: nombre nuevo = nombre viejo || Resumir | `summarise()` | Esta función genera un resumen de nuestros datos ya sean generales o agrupados utilizando la función de abajo `group_by()` || Agrupar | `group_by()` | Esta función agrupa los datos según una variable categórica en particular. |La manera de utilizar estas herramientas es bastante simple. Se escribe la función que necesitemos, se indican los datos en los que vamos a trabajar y luego se indica aquello que necesitemos hacer.### Filtrar```{r message=FALSE}library(tidyverse)```Pseudocodigo```{r eval=FALSE}funcion(datos, lo que necesitamos)```Pseudocodigo con un objetivo más claro```{r eval=FALSE}filtrar(datos, variable mayor que 1)```Codigo para alcanzar el objetivo```{r}filter(.data = starwars, height >175) # En este caso solo necesito aquellos datos de quienes tengan una altura mayor a 175 cmfilter(.data = starwars, species =="Wookiee") # En este caso solo necesito los datos de quienes sean de la especie Wookiee```### SeleccionarPseudocodigo```{r eval=FALSE}seleccionar(datos, variable(s) de interes)```Código```{r}select(.data = starwars, c(name, height, mass, gender)) # En este caso solo me interesaban las variables nombre, altura, masa y generoseleccion1 <-select(.data = starwars, c(name, height, mass, gender))select(.data = seleccion1, -height) # En este caso se puede usar el select para quitar una variable. Eso se hace usando un - antes de la variable que queremos quitar.select(.data = starwars, starts_with("h"))```### CrearPseudocodigo```{r eval=FALSE}crear(datos, variable(s) que necesito crear = contenido)```Código```{r}mutate(.data = seleccion1, altura = height/100) # En este caso vamos a crear una nueva variable que contenta la transformacion de height de centimetros a metros```::: {.callout-tip collapse="true"}## A tener en cuenta!Cuando usemos mutate() con una variable que ya existe en el dataset conviene no sobreescribirla. Esto afectaría la reproducibilidad del código. Lo mejor es generar una nueva variable con algún identificador.Por ejemplo: Cuando cargamos el dataset vemos que la variable de agrupación gender es de tipo chr y lo que necesitamos es que sea un factor. En ese caso se haría lo siguiente:```{r}mutate(.data = seleccion1, gender_fct =as_factor(gender)) # Nos quedan ambas variables y solo utilizamos la que necesitemos```:::### OrdenarPseudocodigo```{r eval=FALSE}ordenar(datos, variable seleccionada)```Código```{r}arrange(.data = starwars, height) # Orden de menor a mayorarrange(.data = starwars, desc(height)) # Orden de mayor a menor```### AcomodarPseudocodigo```{r eval=FALSE}acomodar(datos, variable, antes/despues de)```Código```{r}relocate(.data = seleccion1, gender, .after = name) # En este caso acomodamos gender despues de namerelocate(.data = seleccion1, name, .before = mass) # En este caso acomodamos name despues de mass```### RenombrarPseudocodigo```{r eval=FALSE}renombrar(datos, nombre nuevo = nombre viejo)```Código```{r}seleccion1_traducida <-rename(seleccion1,nombre = name,altura = height,masa_kg = mass,genero = gender)names(seleccion1)names(seleccion1_traducida)```## Pipe, Pipa, Encadenamiento, Tuberias...Los verbos que proporciona dplyr son geniales y muy faciles de utilizar, pero para todo lo que hicimos más arriba se necesito una linea de codigo para cada verbo. Es decir, cada codigo era independiente del otro. Una gran funcion que permite unificar todos los verbos en un solo programa es la pipa, tuberia o lo que se dice piping.Les presento a ella `%>%` el operador del paquete `magrittr`. Lo que hace es **tomar el resultado de una función y pasarla a otra función como argumento. Esto nos permite vincular una secuencia de pasos de análisis. O en otras palabras, utilizar varios verbos de dplyr en un mismo programa.**Por ejemplo: Se necesita seleccionar algunas variables, renombrarlas y crear variables que sean del tipo correcto. Por ultimo, graficar la altura según el sexo del personaje*Sin %\>%*```{r}paso_1 <-select(.data = starwars, c(name, sex, gender, species, mass, height))paso_2 <-rename(.data = paso_1, nombre = name,sexo = sex,genero = gender,especie = species,masa_kg = mass,altura = height)paso_3 <-mutate(.data = paso_2, sexo_fct =as_factor(sexo),genero_fct =as_factor(genero),especie_fct =as_factor(especie))ggplot(data =select(paso_3, c(sexo_fct, altura, genero_fct)), mapping =aes(x = sexo_fct, y = altura)) +geom_boxplot() +coord_flip() +theme_bw()```*Con %\>%*```{r}starwars %>%# Selecciono los datos Y DESPUESselect(name, sex, gender, species, mass, height) %>%#Selecciono las variables Y DESPUESrename(nombre = name, sexo = sex,genero = gender,especie = species,masa_kg = mass,altura = height) %>%# Renombro las variables Y DESPUESmutate(sexo_fct =as_factor(sexo),genero_fct =as_factor(genero),especie_fct =as_factor(especie)) %>%# Creo nuevas variables Y DESPUESggplot()+# Graficogeom_boxplot(mapping =aes(x = sexo_fct, y = altura)) +coord_flip() +theme_bw()```::: {.callout-tip collapse="true"}## Aspectos a tener en cuenta!!- Me encanto la pipa, pero es medio complicada de escribir. Si, es verdad. Para eso usamos el siguiente atajo del teclado `CTRL + SHIFT + M` y ya tenemos la pipa. Con un poco de practica ya sale sola.- Existe otra pipa que fue introducida recientemente. Yo le digo el pinguinito. Es la pipa nativa de R y es así \|\>. En general cumple la misma función. Yo como soy viejo y me acostumbre a usar %\>% entonces sigo con esa. Ustedes usen la que mas les guste y cumpla mejor con sus objetivos. Hay debate sobre que pipa usar. Quedara para otro momento.:::{{< elevator "Ir arriba" >}}