Sexta Reunión
Haciendo tablas con R
Datos
Ver/Ocultar código
Rows: 347
Columns: 10
$ set <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, …
$ numero <chr> "1030", "1040", "1070", "1080", "1200", "1220…
$ desc <chr> "Serpienie", "Serpiente", "Serpiente", "Serpi…
$ valencia_media_general <dbl> 4.22, 3.86, 3.54, 3.93, 3.89, 4.02, 4.37, 3.9…
$ valencia_DE_general <dbl> 2.01, 2.10, 2.01, 2.00, 1.89, 1.89, 1.79, 1.8…
$ arousal_media_general <dbl> 6.22, 7.01, 6.94, 6.35, 6.42, 6.60, 5.76, 5.8…
$ arousal_DE_general <dbl> 2.25, 215.00, 2.20, 2.10, 2.32, 2.15, 2.15, 2…
$ dominancia_media_general <dbl> 4.04, 3.53, 3.83, 3.69, 4.04, 4.42, 4.58, 4.4…
$ dominancia_DE_general <dbl> 2.35, 2.44, 2.73, 2.21, 2.40, 2.56, 2.17, 2.3…
$ pais <chr> "esp", "esp", "esp", "esp", "esp", "esp", "es…Ordenando un poco…
Ver/Ocultar código
datos_ordenados <- datos %>%
select(set, pais, starts_with(c("valencia", "arousal", "dominancia"))) %>% # Con esto selecciono todas las que arrancon con "texto"
mutate(
pais_factor = as_factor(pais)
) %>%
relocate(
c("pais_factor", "pais"), .after = dominancia_DE_general # Acomodo dos variables
)
# Esta es una manera de hacer tablas.
# Usar la función kable de knitr (que es el paquete
# que renderea el documento)
knitr::kable(head(datos_ordenados)) | set | valencia_media_general | valencia_DE_general | arousal_media_general | arousal_DE_general | dominancia_media_general | dominancia_DE_general | pais_factor | pais |
|---|---|---|---|---|---|---|---|---|
| 1 | 4.22 | 2.01 | 6.22 | 2.25 | 4.04 | 2.35 | esp | esp |
| 1 | 3.86 | 2.10 | 7.01 | 215.00 | 3.53 | 2.44 | esp | esp |
| 1 | 3.54 | 2.01 | 6.94 | 2.20 | 3.83 | 2.73 | esp | esp |
| 1 | 3.93 | 2.00 | 6.35 | 2.10 | 3.69 | 2.21 | esp | esp |
| 1 | 3.89 | 1.89 | 6.42 | 2.32 | 4.04 | 2.40 | esp | esp |
| 1 | 4.02 | 1.89 | 6.60 | 2.15 | 4.42 | 2.56 | esp | esp |
Una vez que tenemos los datos que queremos ya podemos generar la tabla. Hay muchas opciones para generar tablas. Una de estas opciones es generarla “a mano”. Tendríamos que hacer las correlaciones y luego incrustar los resultados en cada sección de una tabla.
Veamos:
Para crear la tabla se utiliza markdown. Lo que se debe hacer es lo siguiente:
| Col1 | Col2 | Col3 |
|------|------|------|
| | | |
| | s | |
| | | |Luego se llevan a cabo las correlaciones
Ver/Ocultar código
# Correlation Matrix (pearson-method)
Parameter1 | Parameter2 | r | 95% CI | t(345) | p
-------------------------------------------------------------------------------------------------
set | valencia_media_general | 0.01 | [-0.09, 0.12] | 0.25 | > .999
set | valencia_DE_general | -0.11 | [-0.22, -0.01] | -2.11 | 0.429
set | arousal_media_general | 0.08 | [-0.02, 0.19] | 1.58 | > .999
set | arousal_DE_general | -0.07 | [-0.18, 0.03] | -1.32 | > .999
set | dominancia_media_general | -0.03 | [-0.14, 0.07] | -0.60 | > .999
set | dominancia_DE_general | -0.22 | [-0.32, -0.12] | -4.29 | < .001***
valencia_media_general | valencia_DE_general | 0.06 | [-0.04, 0.16] | 1.13 | > .999
valencia_media_general | arousal_media_general | -0.66 | [-0.71, -0.59] | -16.18 | < .001***
valencia_media_general | arousal_DE_general | -0.03 | [-0.14, 0.07] | -0.62 | > .999
valencia_media_general | dominancia_media_general | 0.38 | [ 0.28, 0.46] | 7.55 | < .001***
valencia_media_general | dominancia_DE_general | -0.34 | [-0.43, -0.24] | -6.73 | < .001***
valencia_DE_general | arousal_media_general | 0.14 | [ 0.03, 0.24] | 2.61 | 0.123
valencia_DE_general | arousal_DE_general | 0.08 | [-0.02, 0.19] | 1.55 | > .999
valencia_DE_general | dominancia_media_general | -0.06 | [-0.17, 0.04] | -1.18 | > .999
valencia_DE_general | dominancia_DE_general | 0.35 | [ 0.25, 0.44] | 6.93 | < .001***
arousal_media_general | arousal_DE_general | 0.09 | [-0.01, 0.20] | 1.77 | 0.857
arousal_media_general | dominancia_media_general | -0.39 | [-0.47, -0.30] | -7.84 | < .001***
arousal_media_general | dominancia_DE_general | 0.39 | [ 0.30, 0.48] | 7.95 | < .001***
arousal_DE_general | dominancia_media_general | -0.04 | [-0.14, 0.07] | -0.68 | > .999
arousal_DE_general | dominancia_DE_general | 0.05 | [-0.05, 0.16] | 0.95 | > .999
dominancia_media_general | dominancia_DE_general | -0.21 | [-0.31, -0.11] | -3.96 | 0.001**
p-value adjustment method: Holm (1979)
Observations: 347Y lo que restaría seria armar la tabla resultado por resultado. El problema de esto es que no es muy reproducible que digamos, es tedioso y puede llevarnos a cometer errores.
ApaTables
Entonces, una de las opciones que podemos utilizar para evitar lo de arriba es el paquete apaTables (Stanley, 2021). Este paquete genera tablas en formato apa luego de realizar la estadística.
Para utilizarlo, primero lo instalamos (Si ya lo tienen, entonces omitir esto)
Luego lo cargamos
Ahora si podemos generar nuestra tabla de correlaciones.
New names:
• `pais_factor` -> `pais_factor...1`
• `pais_factor` -> `pais_factor...4`Si vamos al archivo…
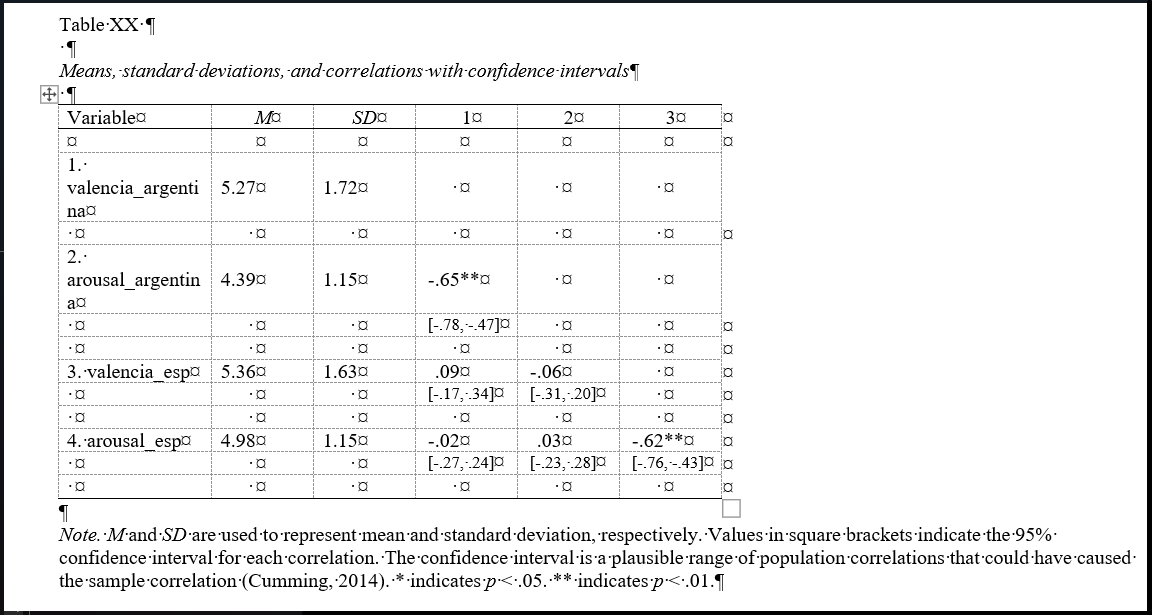
Paquete rempsyc

Integrado con el paquete report
Ver/Ocultar código
Welch Two Sample t-test
data: arousal_media_general by pais_factor
t = 3.3642, df = 332.04, p-value = 0.0008575
alternative hypothesis: true difference in means between group esp and group arg is not equal to 0
95 percent confidence interval:
0.182999 0.698348
sample estimates:
mean in group esp mean in group arg
5.046429 4.605755 Warning: Unable to retrieve data from htest object. Returning an approximate
effect size using t_to_d().Si vamos al archivo…
